
 URL 복사
URL 복사 카카오톡 공유하기
카카오톡 공유하기Solr를 이용한 검색엔진 구현
 mysql-connector-java-5.1.39.jar
[966.3 KB]
arirang.zip
[680.67 KB]
mysql-connector-java-5.1.39.jar
[966.3 KB]
arirang.zip
[680.67 KB]Solr는 Apache Lucene을 기반으로 만들어진 검색엔진입니다.
검색은 크게 데이터 수집, 데이터 색인, 데이터 검색의 프로세스를 가지는데 Lucene은 색인과 검색을 지원해주는 라이브러리 입니다.
Solr를 공부해보고, 본 사이트에 통합검색으로 적용해보았습니다.
공부한 내용을 대략적으로 정리해봅니다.
<br/>
<span style="color:#000000">색인 그리고 검색 합니다.
<br/>
<span style="color:#000000">색인을 하고, 목차를 만든 후, 검색을 합니다.
<span style="color:#000000">색인 작업을 통해 목차를 만들었으니, 빠르게 검색결과를 확인 할 수 있습니다.
<br/>
<br/>
<span style="color:#000000">용어 정리.
-
Core - DB의 테이블과 같은 개념.
-
field - DB의 field와 같은개념
-
fieldType - DB의 자료형과 동일한 개념
<br/>
<br/>
<br/>
<br/>
Solr ver 7.2.1 (+ MySql 연동)
Arirang 7.2.1 버전과 호환됩니다.
<span style="color:#c0392b"># 한글 형태소 분석기(Arirang Analazer) <a href="http://cafe.naver.com/korlucene">(http://cafe.naver.com/korlucene)</a>
<span style="color:#c0392b"># 형태소 분석기란?
<span style="color:#c0392b">문장에서 단어를 분석하는 작업을 한다. 예를들어 “겨울에는 눈이 옵니다” 라는 문구가 있으면, 형태소를 분석하여 “눈”, “겨울”, "옵니다" 등 WORD를 추출합니다.
<br/>
<p style="margin-left:0cm; margin-right:0cm">
본 예제는 Tomcat에 올리는 것이 아닌, 단독서버 운영 시 예제입니다.
<a href="http://archive.apache.org/dist/lucene/solr/">http://archive.apache.org/dist/lucene/solr/</a> 해당 페이지에서 solr.7.2.1을 다운받았습니다.
<p style="margin-left:0cm; margin-right:0cm">
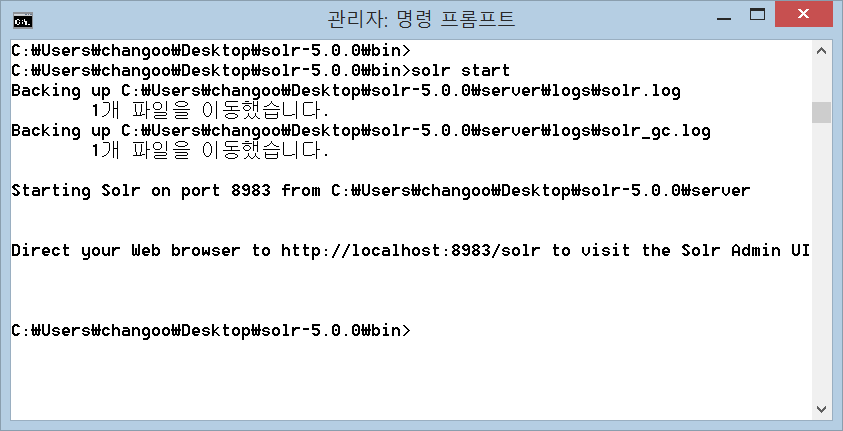
<p style="margin-left:0cm; margin-right:0cm">압축을 푼후 CMD창을 열어 bin 하위폴더 접근합니다.
<p style="margin-left:0cm; margin-right:0cm"><span style="color:#0000ff">solr start 명령을 통해 solr를 실행합니다.
<p style="margin-left:0cm; margin-right:0cm"><span style="font-size:12px"><span style="color:black"><img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/R0TJHC181224235518.PNG" style="border-style:solid; border-width:1px; width:480px"/>
<br/>
<br/>
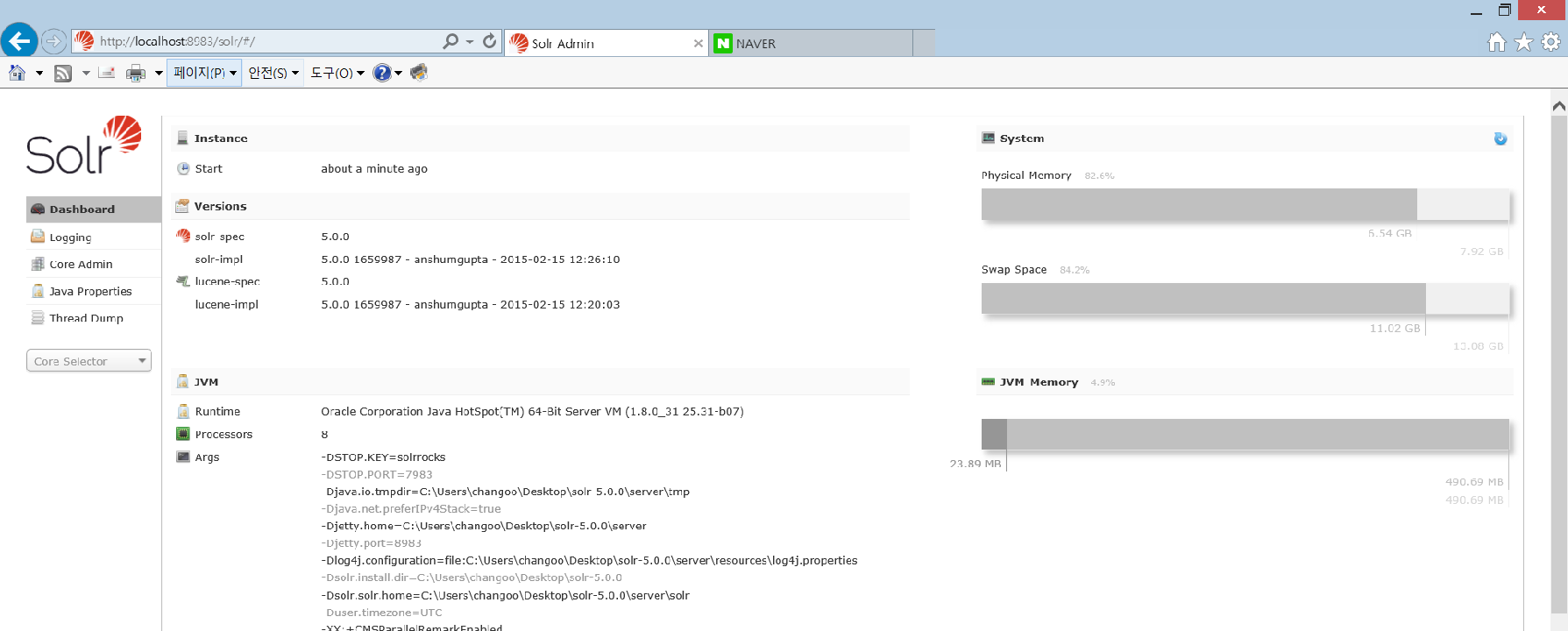
<p style="margin-left:0cm; margin-right:0cm"><a href="http://localhost:8983/solr/#/">http://localhost:8983/solr/#/</a> 해당 페이지로 이동하면, GUI 페이지를 확인 할 수 있습니다.
<p style="margin-left:0cm; margin-right:0cm"><span style="font-size:12px"><span style="color:black"><img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/OQTTKF181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<br/>
다음으로 Core를 생성합니다.
<span style="color:#0000ff">{root}\server\solr\configsets 폴더로 들어가면 <span style="color:#0000ff">_default 폴더를 확인 할 수 있습니다.
복사하여 <span style="color:#0000ff">{root}\server\solr 붙여넣습니다. 폴더이름을 원하는 Core명으로 바꿔줍니다. <span style="color:#0000ff">new_core로 변경하였습니다.
<img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/WJKQSL181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<br/>
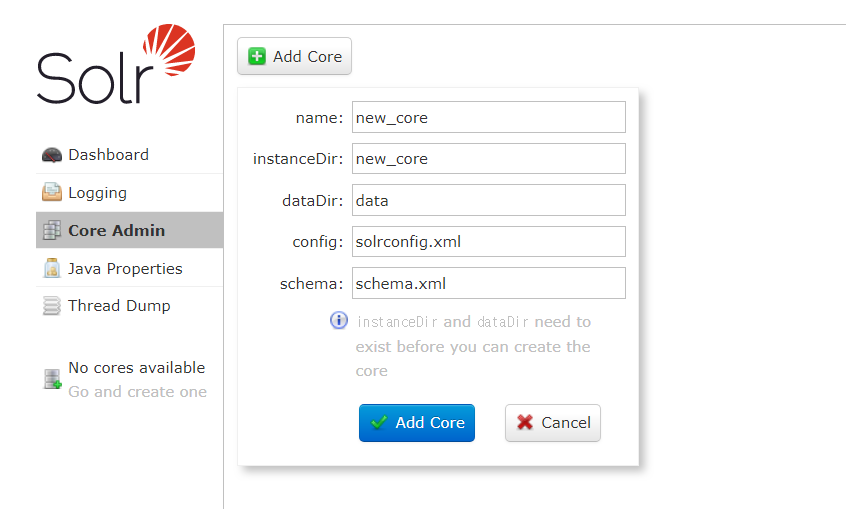
Solr 관리자 페이지에 들어가 instanceDir에 폴더명을 명시 후 생성합니다.
<img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/L9VAPU181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<br/>
라이브러리를 추가해야 합니다.
<span style="color:#0000ff">{root}_LIB 폴더를 생성하였습니다.
해당 폴더에<span style="color:#0000ff"> Arirng 분석기 라이브러리를 붙여 넣었습니다. (파일첨부)
MySql에 접근하여야하니 <span style="color:#0000ff">mysql connect 라이브러리도 붙여넣습니다. (파일첨부)
또한 <span style="color:#0000ff">{root}\dist 폴더의 s<span style="color:#0000ff">olr-dataimporthandler-7.2.1.jar, solr-dataimporthandler-extras-7.2.1.jar 파일도 추가합니다.
<br/>
<br/>
<span style="color:#0000ff">${root}\server\solr\new_core\conf 로 이동하여,
<span style="color:#0000ff">solrconfig.xml에 라이브러리 위치에 다음 코드와 같이 _LIB 폴더를 추가합니다.
<lib dir="${solr.install.dir:../../../..}/_LIB/" regex=".*\.jar" />
<br/>
<br/>
라이브러리가 추가 되었으니, Solr 형태소 분석기에 Arirang 분석기를 사용하는 필드타입을 추가해야합니다.
<span style="color:#0000ff">managed-schema 파일에 다음을 추가합니다. "ko” fieldType을 추가하는 코드입니다.
<fieldType name="ko" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ClassicFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" />
<filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/>
<!--filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ClassicFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" />
<filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/>
<filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
</analyzer>
</fieldType>
이제 필드타입을 "ko"로 설정하면, Arirng 형태소 분석기를 사용하여 한글을 형태소 분석 하게됩니다.
<br/>
<br/>
이제 Core를 생성하였고, Arirang 형태소 분석기도 추가하였습니다.
**DB로부터 데이터를 수집해야합니다. 따라서 Core에 매핑되는 테이블을 준비합니다. **
<br/>
<span style="color:#0000ff">id, title, contents 세 개의 필드를 가지고있는 <span style="color:#0000ff">TB_SOLR_EXMP 테이블을 생성하였습니다.
적지만 샘플 레코드도 추가하였습니다.
<img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/NQHORR181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<br/>
MySQl과 커넥션을 위한 설정이 필요할 것입니다.
<span style="color:#0000ff">{root}\server\solr\new_core\conf에<span style="color:#0000ff"> data-config.xml 파일을 생성하고 다음을 입력합니다.
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource
driver="com.mysql.jdbc.Driver"
url="{url입력}"
user="{아이디 입력}"
password="{패스워드 입력}" />
<document>
<entity pk="id" name="TB_SOLR_EXMP" query="SELECT * FROM TB_SOLR_EXMP" >
<field column="id" name="id"/>
<field column="title" name="title"/>
<field column="contents" name="contents"/>
</entity>
</document>
</dataConfig>
field 태그의 column은 테이블의 필드명을,
field 태그의 name은 solr의 필드명을 말합니다.
<br/>
<br/>
가져온 데이터의 필드에 대해서 어떤 필드타입으로 처리할지를 정의해야 합니다.
<span style="color:#0000ff">managed-schema 파일에 다음과 같이 설정하여, 필드 타입을 정의합니다.
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="title" type="ko" indexed="true" stored="true"/>
<field name="contents" type="ko" indexed="true" stored="true"/>
<uniqueKey>id</uniqueKey>
title, contents는 한글 형태소 분석을 필요로하므로 type을 ko로 지정합니다.
Primary key도 uniqueKey 태그를 통해 지정합니다.
<br/>
<span style="color:#0000ff">solrconfig.xml에는 다음을 추가합니다.
<span style="color:#0000ff">/dataimport <span style="color:null">요청에<span style="color:#0000ff"> data-config.xm<span style="color:null">l 설정에 따라 데이터를 가져 올 것 입니다.
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
<p style="margin-left:0cm; margin-right:0cm">
<br/>
<br/>
<br/>
모든 설정이 마무리 되었습니다.
Solr를 재실행하고,
<a href="http://localhost:8983/solr/new_core/dataimport/">http://localhost:8983/solr/new_core/dataimport/</a> 요청하면 DB로 부터 데이터를 받아 색인작업을 실행한합니다.
<a href="http://localhost:8983/solr/new_core/select?q=%3A&wt=json&indent=true">http://localhost:8983/solr/new_core/select?q=%3A&wt=json&indent=true</a> 요청하면, 다음과 같이 데이터가 삽입되었음을 확인할 수 있습니다.
{
"responseHeader":{
"status":0,
"QTime":7,
"params":{
"q":"*:*",
"indent":"true",
"wt":"json"}},
"response":{"numFound":4,"start":0,"docs":[
{
"contents":"속담은 예로부터 한 민족 혹은 사회에서 사람들 사이에서 널리 말하여져서 굳어진 어구로 전해지는 말이다. 격언이나 잠언과 유사하다. 속담은 그 속담이 통용되는 공동체의 의식 구조를 반영하기 때문에 언어학이나 문화인류학 등에서 연구 대상으로 많이 삼고 있다. 문학 작품에도 많이 등장한다. 위키백과",
"id":"1",
"title":"속담",
"_version_":1590284565258174464},
{
"contents":"크리스마스에는 눈이 옵니다",
"id":"2",
"title":"크리스마스",
"_version_":1590284565646147584},
{
"contents":"겨울에도 눈이 옵니다",
"id":"3",
"title":"눈온다",
"_version_":1590284565647196160},
{
"contents":"안녕하세요 이찬구입니다.",
"id":"4",
"title":"인사",
"_version_":1590284565648244736}]
}}
<br/>
<br/>
<br/>
SolrJ 사용하기. v7.2.1
앞서 Solr의 모든 설정이 끝나고 MySql과의 커넥션도 마무리하였습니다.
이제 SolrJ 라이브러리를 통하여 Java단에서 Solr로 접근할 수 있습니다.
간단한 검색엔진 웹페이지를 만들어봅시다.
<br/>
우선 웹프로젝트에 SolrJ 라이브러리를 추가합니다.
Pom.xml에 다음을 삽입합니다.
<!-- Solr -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.1.0</version>
</dependency>
<p style="margin-left:0cm; margin-right:0cm">
<p style="margin-left:0cm; margin-right:0cm">프론트단에 간단한 검색창을 구현하였습니다.
<p style="margin-left:0cm; margin-right:0cm">버튼을 누르면 값과 함께 /search 가 요청 됩니다.
<p style="margin-left:0cm; margin-right:0cm"><span style="font-size:11pt"><span style="color:black"><img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/GT5E5P181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<br/>
검색 요청을 받으면 다음과 같이 동작합니다.
@WebServlet("/search")
public class SearchServlet extends HttpServlet {
private final String url = "http://localhost:8983/solr/new_core";
private SolrClient solr;
public SearchServlet() {
solr = new HttpSolrClient(url);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String searchValue = request.getParameter("sh");
SolrQuery query = new SolrQuery();
query.setQuery("contents:" + searchValue);
try {
QueryResponse rsp = solr.query(query);
SolrDocumentList docs = rsp.getResults();
request.setAttribute("searchResult", docs);
RequestDispatcher rd = request.getRequestDispatcher("search_result.jsp");
rd.forward(request, response);
} catch (SolrServerException e) {
e.printStackTrace();
}
}
}
-
7 : SolrClient는 Solr에 접근하는 객체이다.
-
12 ~ 13: SolrQuery 객체를 통해서 solr 쿼리문을 정의한다. 위의 예제는 “contents” 내용 중 searchValue가 포함된 row를 가져온다.
-
16 : SolrDocumentList객체는 검색된 레코드이다.
-
18 : request Attribute에 주입하여, 프론트단으로 넘긴다.
<br/>
<br/>
<br/>
프론트단에서는 다음과 같이 뿌려줍니다.
<%
SolrDocument doc = null;
SolrDocumentList docs = (SolrDocumentList)request.getAttribute("searchResult");
for (int i = 0; i < docs.size(); i++) {
doc = docs.get(i);
%>
<div class="search-row">
<span class="search-fd"><%=doc.get("title")%>
<span class="search-fd"><%=doc.get("contents")%>
**
<%} %>
<p style="margin-left:0cm; margin-right:0cm">
<p style="margin-left:0cm; margin-right:0cm">
<p style="margin-left:0cm; margin-right:0cm">Solr를 통한 검색 결과를 확인 할 수 있습니다.
<p style="margin-left:0cm; margin-right:0cm"><img alt="" src="https://static.podo-dev.com/blogs/images/2019/07/10/origin/KCM6XJ181224235519.PNG" style="border-style:solid; border-width:1px; width:480px"/>
{kind=link}
<br/>
<p style="margin-left:0cm; margin-right:0cm">